In this tutorial we will create an automated pipeline which creates three droplets on DigitalOcean. We will have a script running on each droplet, which will create important files constantly. To backup those file regularly we will extend our infrastructure code to not only create three droplets, but also one DigitalOcean Volume for each droplet. Volumes offer block storage which can simply be mounted to our droplets. Perfect to keep our backups.
When the droplets are destroyed/recreated (when changing the droplet’s infrastructure code) the worker scripts running on our droplets will look for backups in the mounted DigitalOcean Volume so that it can continue from the last backups state.
To let terraform (the tool that will automatically create/manage our infrastructure on AWS and DigitalOcean as we described it in our infrastructure code) always know about the current state of all our infrastructure resources (droplets and volumes) we will use an AWS S3 bucket as a terraform backend to save the terraform.tfstate.
What you need if you want to try out this example for yourself is an account for Amazon AWS (access key and secret key) and a DigitalOcean account. AWS offers a free tier where you are allowed to create S3 buckets without costs as long as you don’t upload more than 5GB. If you don’t have a DigitalOcean account yet, feel free to use my referral link and get 100$ credit for free to try things out without costs: Create account
So let us directly jump into action. The steps we will do are the following:
- Create the infrastructure code which will create our droplets and volumes and mount the volumes onto the corresponding droplets.
- create the worker script which will run on each droplet and create the files we want to backup.
- create a cronjob which will do the backups in regular intervals
- create the gitlab-ci.yml which will contain the code describing what our pipeline should do (execute terraform to build our infrastructure).
Here is an overview of the complete project (you can find the project here on gitlab):
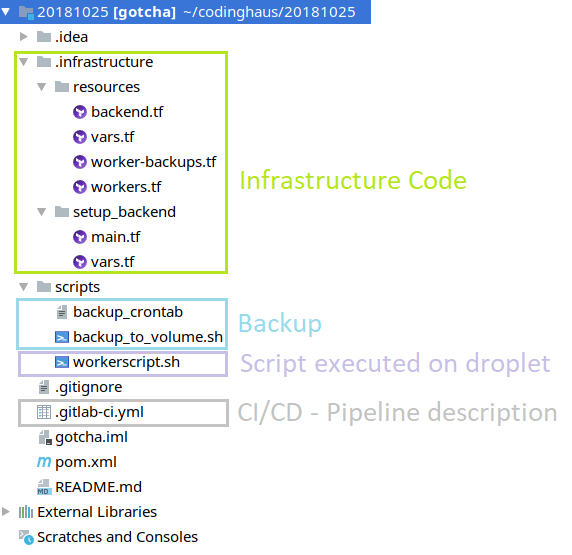
Let us start:
Create the infrastructure code
The infrastructure code is split into two folders. First let us have a look at ’setup_backend‘:
provider "aws" {
region = "${var.AWS_REGION}"
access_key = "${var.AWS_ACCESSKEY}"
secret_key = "${var.AWS_SECRETKEY}"
}
resource "aws_s3_bucket" "terraform_state" {
bucket = "${var.AWS_BUCKET_NAME}"
versioning {
enabled = true
}
lifecycle {
prevent_destroy = true
}
}
It only contains the S3 bucket resource. So the only purpose is to create that bucket. In our pipeline code, we will add an if statement where we will check if the S3 bucket already exists. And only if it doesn’t exist we will tell terraform to create that resource.
You can find the if-statement in the code snippet from our gitlab-ci.yml below. It looks like:
if aws s3api head-bucket --bucket "de.codinghaus.s3" 2>/dev/null ; then echo "Skipping Backend-Creation, S3-Bucket already existing!"; else cd setup_backend && terraform init && terraform plan && terraform apply -auto-approve && cd ..; fi
If you wonder where the variables come from, have a look at vars.tf:
variable "AWS_REGION" {}
variable "AWS_TF_STATEFILE" {}
variable "AWS_BUCKET_NAME" {}
variable "AWS_ACCESSKEY" {}
variable "AWS_SECRETKEY" {}
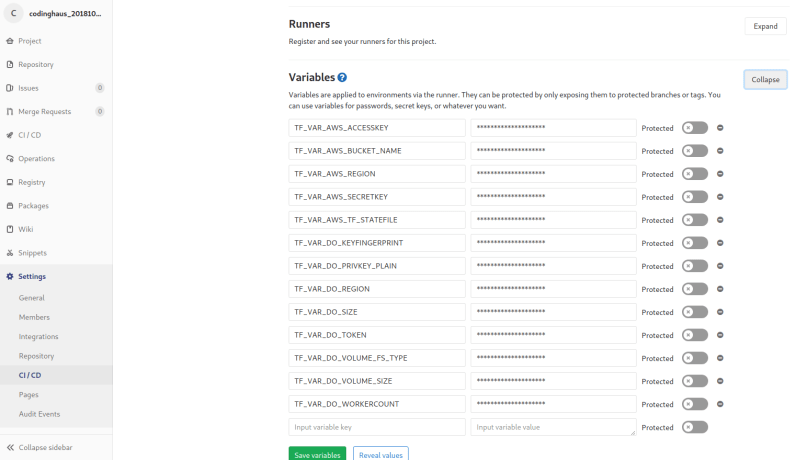
Yes, they are empty. We do not want our AWS-Keys to appear in our source code. So what we do is the following: We use gitlab CI/CD environment variables which can be found at „Settings“ –> „CI/CD“ –> „Variables“. There we can add environment variables which are available on the pipeline runners, where our pipeline code is executed. terraform will now recognize, that we defined variables in vars.tf. Then it will try to find values for those variables. As we didn’t set values at the definition, terraform will next search for environment variables in the form of TF_VAR_. So e.g. for AWS_REGION terraform will look for an environment variable TF_VAR_AWS_REGION. As terraform is executed on the gitlab runner, we only have to define the needed gitlab environment variables and terraform will find them including their values:
‚resources‘ is the main folder which contains the code for three droplets, three volumes and the attachments from droplet to volume. It also contains the definition of the backend resource (in our case the S3 bucket).
First let us have a look at the droplet resources in workers.tf:
provider "digitalocean" {
token = "${var.DO_TOKEN}"
}
/* here we tell terraform to create three droplets (as we defined
the gitlab environment variable TF_VAR_DO_WORKERCOUNT = 3). The names
will be worker0X (worker01, worker02 and worker03).*/
resource "digitalocean_droplet" "worker" {
image = "ubuntu-16-04-x64"
name = "${format("worker%02d", count.index + 1)}"
count = "${var.DO_WORKERCOUNT}"
region = "${var.DO_REGION}"
size = "${var.DO_SIZE}"
private_networking = true
ssh_keys = [
"${var.DO_KEYFINGERPRINT}"
]
connection {
user = "root"
type = "ssh"
private_key = "${file("~/.ssh/id_rsa")}"
timeout = "2m"
}
/* now we will copy the workerscript and the the backup /cronjob stuff
onto the droplet)
provisioner "file" {
source = "../../scripts/workerscript.sh"
destination = "/workerscript.sh"
}
provisioner "file" {
source = "../../scripts/backup_to_volume.sh"
destination = "/etc/backup_to_volume.sh"
}
provisioner "file" {
source = "../../scripts/backup_crontab"
destination = "/etc/cron.d/backup_crontab"
}
/* as the last step during the droplet creation, we give all scripts
the execute flag, install zip which is needed the create the
backups in zipped form and run the workerscript (see below). /*
provisioner "remote-exec" {
inline = [
"sleep 10",
"chmod +x /workerscript.sh",
"chmod +x /etc/backup_to_volume.sh",
"chmod +x /etc/cron.d/backup_crontab",
"apt-get install zip -y",
"nohup bash /workerscript.sh &",
"sleep 2"
]
}
}
Now, that the droplets are created, let us have a look at the code describing our volumes:
/* the first resource block describes our volumes. It will be executed
after the droplet creation has finished (see the depends_on attribute).
the name of each volume will be worker0X-backup. */
resource "digitalocean_volume" "worker-backup-volume" {
count = "${var.DO_WORKERCOUNT}"
region = "${var.DO_REGION}"
name = "${format("worker%02d", count.index + 1)}-backup"
size = "${var.DO_VOLUME_SIZE}"
initial_filesystem_type = "${var.DO_VOLUME_FS_TYPE}"
depends_on = ["digitalocean_droplet.worker"]
/* this ensures that terraform will never try to destroy/recreate
our volumes (which contain our importand backups!) /*
lifecycle {
prevent_destroy = true
}
}
/* when the droplets and the volumes exist, it is time to couple
each volume to each droplet. Therefore we can use the
digitalocean_volume_attachment resource type. */
resource "digitalocean_volume_attachment" "worker-backup-volume-attachments" {
count = "${var.DO_WORKERCOUNT}"
droplet_id = "${element(digitalocean_droplet.worker.*.id, count.index)}"
volume_id = "${element(digitalocean_volume.worker-backup-volume.*.id, count.index)}"
depends_on = ["digitalocean_volume.worker-backup-volume"]
}
At last, let us have a look at backend.tf
provider "aws" {
region = "${var.AWS_REGION}"
access_key = "${var.AWS_ACCESSKEY}"
secret_key = "${var.AWS_SECRETKEY}"
}
/* this tells terraform where to look for the current state of
our infrastructure (in the form of a terraform.tfstate file).
We are not able to use variable references in the backend definition.
Therefore we have the values hard coded here. But still .. we don't
want sensitive data (aws keys) in the code here. So we will once again
use gitlab environment variables here. We will run the following in
our gitlab pipeline script:
terraform init -backend-config="access_key=$TF_VAR_AWS_ACCESSKEY" -backend-config="secret_key=$TF_VAR_AWS_SECRETKEY"
which will contain the two keys.
*/
terraform {
backend "s3" {
bucket = "de.codinghaus.s3"
key = "dovolumetutorial_terraform.tfstate"
region = "eu-central-1"
access_key = ""
secret_key = ""
}
}
Create the worker script
#!/bin/bash
mkdir /workdir
touch workerscript.log
# wait until backup volume is mounted
while [ ! -d /mnt/$HOSTNAME\_backup ]
do
echo "waiting for DO-Volume to be mounted...." >> workerscript.log
sleep 10
done
echo "DO-Volume is now mounted!" >> workerscript.log
# restore backup from volume to droplet if existing
newestBackup=$(ls -Frt /mnt/$HOSTNAME\_backup | grep "[^/]$" | tail -n 1)
if [ -z "$newestBackup" ]; then
echo "No backup found on DO-Volume!" >> workerscript.log
else
cp /mnt/$HOSTNAME\_backup/$newestBackup /workdir
unzip /workdir/$newestBackup -d /workdir
rm -rf /workdir/$newestBackup
echo "Found backup ($newestBackup) on DO-Volume! Copied and unzipped it into working directory!" >> workerscript.log
fi
newestFile=$(ls -Frt /workdir | grep "[^/]$" | tail -n 1)
counter=0
if [ -z "$newestFile" ]; then
echo "No previous file found. Starting with 1!" >> workerscript.log
counter=1
else
echo "Found file to start with! ($newestFile)" >> workerscript.log
((counter+=$newestFile))
((counter+=1))
fi
while [ 1 ]; do
sleep 5
fallocate -l 1M /workdir/$counter
echo "Created file: $counter" >> workerscript.log
((counter+=1))
done
When the script is started (which is the case when our droplets were (re-)created) it checks whether the volume is already mounted and if not waits until it is. This is necessary because the script is executed at the end of the remote-exec block of the worker resource (which are the droplets). The volumes are created AFTER the the worker droplets. So the script will be executed before the volumes are created and therefore before they are mounted onto the droplets.
When the volume is mounted, the script checks if there are backups in the volume mount directory. If so the newest backup is copied to the /workdir and unzipped. The file creation then continues from the backup’s last file. If there is no backup the script will start to create file 0. Whether there was a backup or not, the script will then – in the main loop – create a file every five seconds.
Create a cronjob
Well, this is pretty straight-forward. We need a crontab which is copied to /etc/cron.d (see infrastructure code / worker.tf):
*/5 * * * * root /etc/backup_to_volume.sh
and the script doing the backup:
#!/bin/bash
date=$(date +%s)
timestamp=$(date +"%Y_%m_%d_%H_%M")
if [ ! -d /mnt/$HOSTNAME\_backup ]; then
echo "----- ZIPPING FILES AND COPYING ZIP TO DO-VOLUME (1/2) -----"
cd /workdir
zip -r $timestamp-backup.zip ./*
mv $timestamp-backup.zip /mnt/$HOSTNAME\_backup
echo "----- DELETING OUTDATED BACKUPS (2/2) -----"
cd /mnt/$HOSTNAME\_backup
ls -tp | grep -v '/$' | tail -n +6 | xargs -I {} rm -- {} #https://stackoverflow.com/questions/25785/delete-all-but-the-most-recent-x-files-in-bash
fi
As you can see the script is divided into two parts.
- First we create a zip-file containing all files our worker script created into /workdir. That zip file is then uploaded to the volume (the cool thing is that it seems as if we are just moving the zip file into another directory because we mounted our volume into that directory).
- In the second part we delete the most outdated backups (only keeping the 5 newest)
Create the gitlab-ci.yml
stages:
- deploy-infrastructure
deploy-infrastructure:
stage: deploy-infrastructure
image:
name: hashicorp/terraform:light
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
before_script:
- apk add --no-cache python3
- apk add --no-cache curl
- apk add --no-cache bash
- mkdir -p ~/.ssh
- echo "$TF_VAR_DO_PRIVKEY_PLAIN" | tr -d '\r' > ~/.ssh/id_rsa
- chmod -R 700 ~/.ssh
- curl -O https://bootstrap.pypa.io/get-pip.py
- echo "export PATH=~/.local/bin:$PATH" >> ~/.bash_profile
- python3 get-pip.py --user
- source ~/.bash_profile
- pip install awscli --upgrade --user
- aws configure set aws_access_key_id $TF_VAR_AWS_ACCESSKEY
- aws configure set aws_secret_access_key $TF_VAR_AWS_SECRETKEY
script:
- cd .infrastructure
- if aws s3api head-bucket --bucket "de.codinghaus.s3" 2>/dev/null ; then echo "Skipping Backend-Creation, S3-Bucket already existing!"; else cd setup_backend && terraform init && terraform plan && terraform apply -auto-approve && cd ..; fi
- cd resources
- terraform init -backend-config="access_key=$TF_VAR_AWS_ACCESSKEY" -backend-config="secret_key=$TF_VAR_AWS_SECRETKEY"
- terraform plan
- terraform apply -auto-approve
only:
- master
We only have one stage here. In the before_script-block we first add our private key to ~/.ssh/id_rsa to be able to connect to the droplets via ssh (from the gitlab runner). After that we install and configure awscli which we need to check if the S3 bucket is already existing or if it has to be created.
After checking (and creating) the S3 bucket we run the three terraform commands: init, plan and apply which will create our infrastructure in the first run, and then recreate (or not) in all future runs. During the init step (with our backend-config given) terraform will look at the terraform.tfstate file in the S3 bucket so it knows what the current state of our infrastructure is and if there is a need to (re-)create resources or not.
Now that we have everything we need, we have to do one more thing: Create the environment variables in gitlab. You can find/add them under „Settings“ –> „CI/CD“ –> „Variables“.
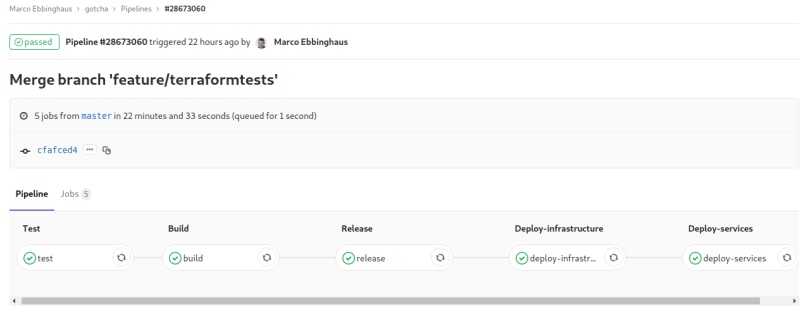
If we push our code the first time the pipeline will start and terraform will create an AWS S3 bucket and then create our infrastructure (left screenshot). From the second pipeline run on there is no need to create the S3 bucket as it already exists. Our pipeline script will recognize this and terraform will initialize the backend to know if our already existing resources need to be recreated (right screenshot).


After the pipeline finishes, let us have a look at the DigitalOcean-GUI and check that everything is there:


Now we will let the infrastructure run some time and see how the backups are created on the volumes.
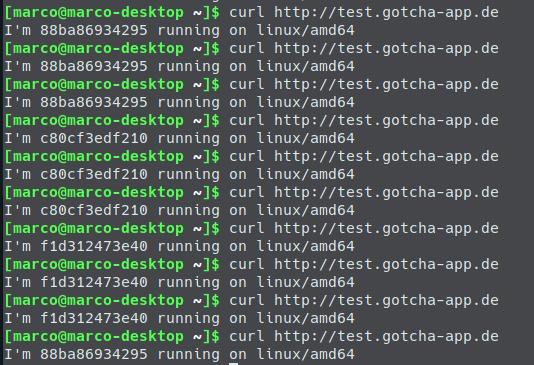
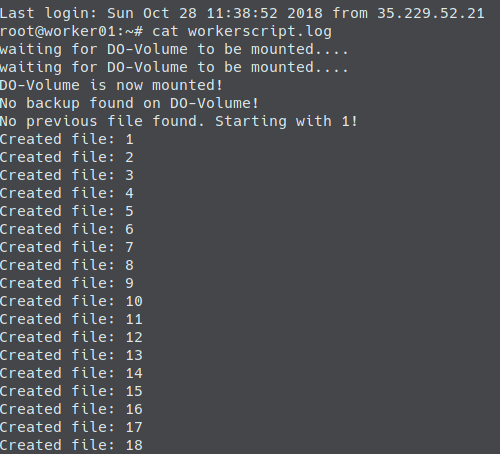
When we connect to our droplet via ssh and have a look at the workerscript log we will see:
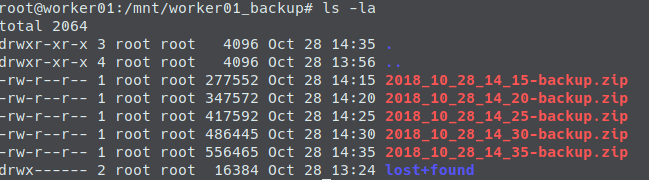
After a couple of minutes let us see what’s inside our backup directory. We will find some uploaded backups now:
Okay, as it seems everything works. Now, we want to see if the backup mechanism works. Oh, have a look at our worker droplet’s image in the workers.tf.. it is ubuntu 16.04:
resource "digitalocean_droplet" "worker" {
image = "ubuntu-16-04-x64"
....
A pretty old ubuntu version! We now want to update that to ubuntu 18.04. So we will change workers.tf to:
resource "digitalocean_droplet" "worker" {
image = "ubuntu-18-04-x64"
....
Then we will push that change. During the triggered pipeline run, terraform will now recognize that the image for the worker droplets was changed. It will decide, that it has to destroy the three droplets and recreate them. The volumes will stay untouched: Nothing changed here and they are marked as undestroyable anyways. But the attachments for the volumes have to change, because the droplet ids will change. No problem: Terraform will automatically destroy the attachments and recreate them.
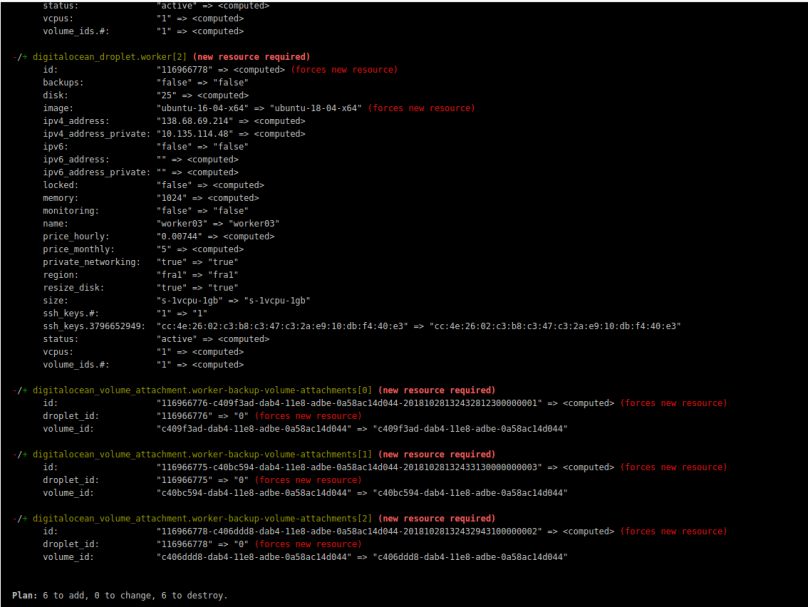
When the triggered pipeline run is finished after the push we only have one problem:
Yes, the droplets were recreated and the attachments for their volumes, too. But (in contrast to the initial creation) the volumes are not automatically mounted onto our droplets (this was a new insight for me when writing this tutorial, I assumed it would be mounted again automatically). The result: Our workerscript will stay forever in the loop waiting for volume to be mounted:
# wait until backup volume is mounted
while [ ! -d /mnt/$HOSTNAME\_backup ]
do
echo "waiting for DO-Volume to be mounted...." >> workerscript.log
sleep 10
done
Well..unexpected.. but let us fix this in a simple (naive) way: We have two cases. The initial creation of our infrastructure (including the automatical mount of our volumes onto the droplets), and recreation of our droplets (not including the automatical mount of our volumes). We will extend the loop and assume, that if after two minutes no volume is mounted, we are in the latter case. And so we will then try to mount the volume manually:
# wait until backup volume is mounted
loopCount=0
while [ ! -d /mnt/$HOSTNAME\_backup ]
do
echo "waiting for DO-Volume to be mounted...." >> workerscript.log
sleep 10
((loopCount+=10))
if (( loopCount > 120 )); then
echo "Volume not mounted after two minutes, trying manual mount..." >> workerscript.log
mkdir -p /mnt/$HOSTNAME\_backup; mount -o discard,defaults /dev/disk/by-id/scsi-0DO_Volume_$HOSTNAME-backup /mnt/$HOSTNAME\_backup; echo /dev/disk/by-id/scsi-0DO_Volume_$HOSTNAME-backup /mnt/$HOSTNAME\_backup ext4 defaults,nofail,discard 0 0 | sudo tee -a /etc/fstab
fi
done
The one liner for the manual mount was copied from the DigitalOcean-GUI (see screenshot below). I just replaced the hard coded hostname with the $HOSTNAME environment variable.

With that change in our waiting loop, the result of a second run of the pipeline (including the recreation of the droplets / attachments) looks like the following:
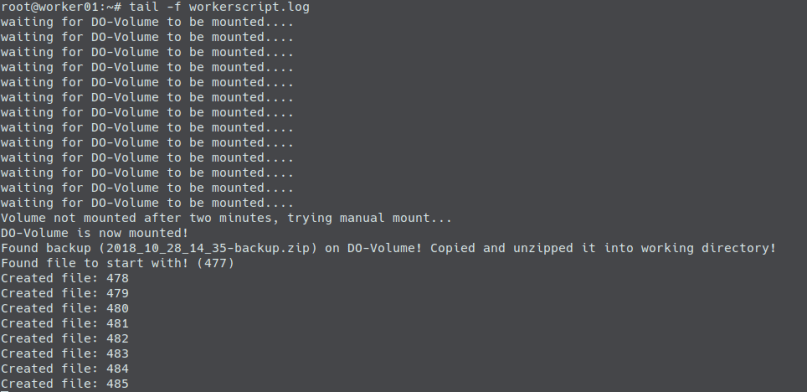
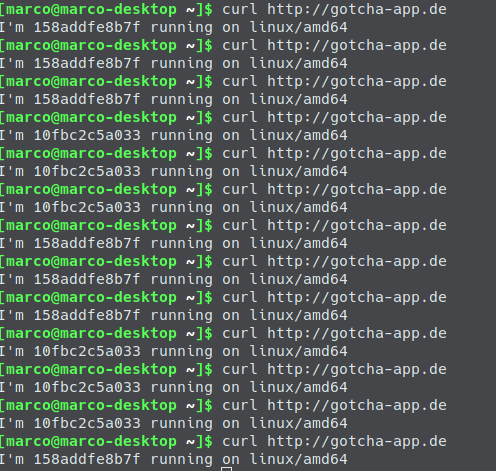
As you can see, the backups from the volume are now found. The newest is taken and our worker script will continue from the state from the newest backup.
Yay!
As already mentioned you can find the full example code at gitlab on https://gitlab.com/mebbinghaus/codinghaus_20181028_dovolumes_backup
If you have questions or feedback, feel free to leave a comment or contact me via twitter or mail.
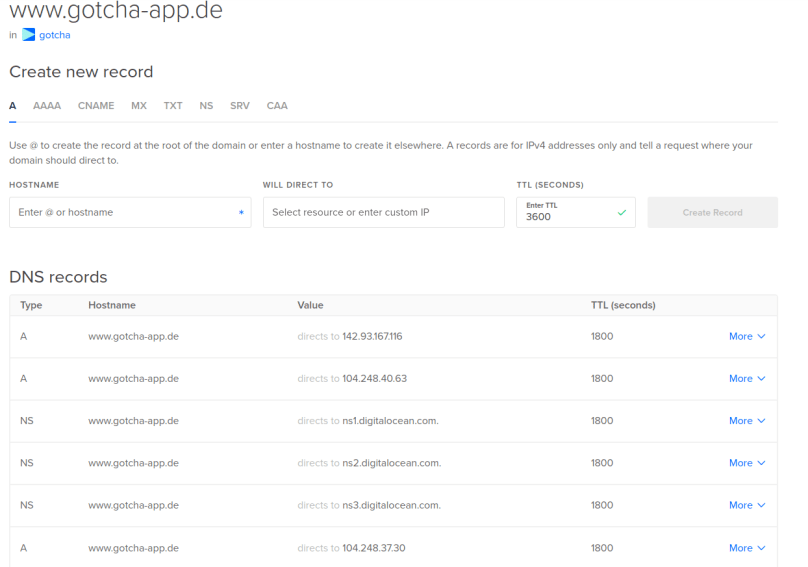
 You only have to do that once (and then wait up to 48 hours) and so this task is not part of our automated pipeline. After this, when creating sub domains via the DigitalOcean API, every created sub domain will automatically contain the three needed NS entries.
You only have to do that once (and then wait up to 48 hours) and so this task is not part of our automated pipeline. After this, when creating sub domains via the DigitalOcean API, every created sub domain will automatically contain the three needed NS entries.