Hey friends,
I finally finished to implement a continuous delivery/deployment pipeline for my java based microservice architectured application which is hosted on Gitlab and running on a swarm mode cluster on DigitalOcean (created/deployed automatically by Terraform). In this article I want to share an overview of the way I got everything running (I won’t go too deep into details because that would make the article too long, but if you are interested in more informations about any part feel free to contact me). This is not meant to be a best practice or the best way to implement it because I don’t know if it is..quite contrary – I’m pretty sure there are smarter ways to do it and it is still work in progress. But maybe you get some inspiration by the way I did it.
My application is a search engine infrastructure (the gui for the search engine is still missing) and consists (as by now) of three microservices (crawler, index and a gui for configuring the crawler) and four jar-files which are created. I will skip the source code of the application and just tell you how the jar files / microservices relate / work together.
The crawler microservice is for scanning the net and collecting everything that was found. It uses Nutch as the crawl engine. Besides Nutch I created an api-service as a jar file, which is also running in the nutch/crawler-container and which is used by the crawler-gui-microservice for communication (configuration/control of the crawler).
The crawler gui is a vaadin 10 frontend application which uses the crawler api to display informations of the crawler and which offers screens for configuring/controlling the crawler.
The last microservice is the index. When the crawler has finished one crawling cycle (which always repeats via a cronjob) it pushes the crawled data to the index-service (based on solr) which makes the data searchable (so the index will be used by the search engine gui microservice which is about to be implemented next).
Info on persistence: I am using GlusterFS to generate one Gluster-Volume for the crawler and one Gluster-Volume for the index. Those volumes are mounted as bind-mounts on every swarm mode cluster node so that the crawled/indexed data are reachable from every cluster node – so it is not important on which node a service is running.
The application code is hosted on Gitlab and I am using the free gitlab ci runners for my CI/CD-Pipeline. The running application itself is hosted/deployed on droplets from DigitalOcean.
Gitlab CI works by defining a gitlab-ci.yml on the top level of a repository and this is what my file looks like:
image: maven:latest
services:
- docker:dind
cache:
paths:
- .m2/repository
variables:
DOCKER_HOST: tcp://docker:2375
DOCKER_DRIVER: overlay2
MAVEN_OPTS: "-Dmaven.repo.local=.m2/repository"
stages:
- test
- build
- release
- deploy-infrastructure
- deploy-services
test:
stage: test
script:
- mvn clean test
only:
- master
build:
stage: build
script:
- mvn clean install
artifacts:
paths:
- gotcha-crawler/gotcha-crawler-webgui/target/gotcha-crawler-webgui-0.1-SNAPSHOT.jar
- gotcha-crawler/gotcha-crawler-api/target/gotcha-crawler-api-0.1-SNAPSHOT.jar
only:
- master
release:
stage: release
image: docker:latest
before_script:
- docker login $TF_VAR_DOCKER_REGISTRY_URL --username $TF_VAR_DOCKER_REGISTRY_USERNAME --password $TF_VAR_DOCKER_REGISTRY_PASSWORD
script:
- docker build --tag=gotcha-index ./gotcha-index
- docker tag gotcha-index docker.gotcha-app.de/gotcha/index:latest
- docker push docker.gotcha-app.de/gotcha/index
- docker build --tag=gotcha-crawler ./gotcha-crawler
- docker tag gotcha-crawler docker.gotcha-app.de/gotcha/crawler:latest
- docker push docker.gotcha-app.de/gotcha/crawler
- docker build --tag=gotcha-crawlergui ./gotcha-crawler/gotcha-crawler-webgui
- docker tag gotcha-crawlergui docker.gotcha-app.de/gotcha/crawlergui:latest
- docker push docker.gotcha-app.de/gotcha/crawlergui
only:
- master
deploy-infrastructure:
stage: deploy-infrastructure
image:
name: hashicorp/terraform:light
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
before_script:
- apk add --no-cache python3
- apk add --no-cache curl
- mkdir -p ~/.ssh
- echo "$TF_VAR_DO_PRIVKEY_PLAIN" | tr -d '\r' > ~/.ssh/id_rsa
- chmod -R 700 ~/.ssh
- curl -O https://bootstrap.pypa.io/get-pip.py
- python3 get-pip.py --user
- touch ~/terraform.log
- chmod 777 ~/terraform.log
- echo "export PATH=~/.local/bin:$PATH" >> ~/.bash_profile
- echo "export TF_LOG_PATH=~/terraform.log" >> ~/.bash_profile
- echo "export TF_LOG=TRACE" >> ~/.bash_profile
- source ~/.bash_profile
- pip install awscli --upgrade --user
- aws configure set aws_access_key_id $TF_VAR_AWS_ACCESSKEY
- aws configure set aws_secret_access_key $TF_VAR_AWS_SECRETKEY
script:
- cd .infrastructure
- if aws s3api head-bucket --bucket "de.gotcha-app.s3" 2>/dev/null ; then echo "Skipping Backend-Creation, S3-Bucket already existing!"; else cd setup_backend && terraform init && terraform plan && terraform apply -auto-approve && cd ..; fi
- cd live/cluster
- terraform init -backend-config="access_key=$TF_VAR_AWS_ACCESSKEY" -backend-config="secret_key=$TF_VAR_AWS_SECRETKEY"
- terraform plan
- until terraform apply -auto-approve; do echo "Error while using DO-API..trying again..."; sleep 2; done
- ls -la
- pwd
artifacts:
paths:
- ~/terraform.log
only:
- master
deploy-services:
stage: deploy-services
before_script:
- echo "deb http://ppa.launchpad.net/ansible/ansible/ubuntu trusty main" >> /etc/apt/sources.list
- apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
- apt-get update
- apt-get install ansible -y
- apt-get install jq -y
script:
- mkdir -p /root/.ssh
- echo "$TF_VAR_DO_PRIVKEY_PLAIN" | tr -d '\r' > ~/.ssh/id_rsa
- chmod -R 700 ~/.ssh
- "GOTCHA_MASTER_IP=$(curl -sX GET https://api.digitalocean.com/v2/droplets -H \"Authorization: Bearer $TF_VAR_DO_TOKEN\" | jq -c '.droplets[] | select(.name | contains(\"gotchamaster00\")).networks.v4[0]'.ip_address)" # extrahieren der IP-Adresse von gotchamaster00 via DO-API und jq anhand des dropletnamens
- GOTCHA_MASTER_IP="${GOTCHA_MASTER_IP%\"}"
- GOTCHA_MASTER_IP="${GOTCHA_MASTER_IP#\"}"
- echo "$GOTCHA_MASTER_IP"
- export GOTCHA_MASTER_IP
- echo $GOTCHA_MASTER_IP > /etc/ansible/hosts
- scp -o StrictHostKeyChecking=no docker-compose.yml root@$GOTCHA_MASTER_IP:/root/docker-compose.yml
- ansible all --user=root -a "docker stack deploy --compose-file docker-compose.yml --with-registry-auth gotcha"
only:
- master
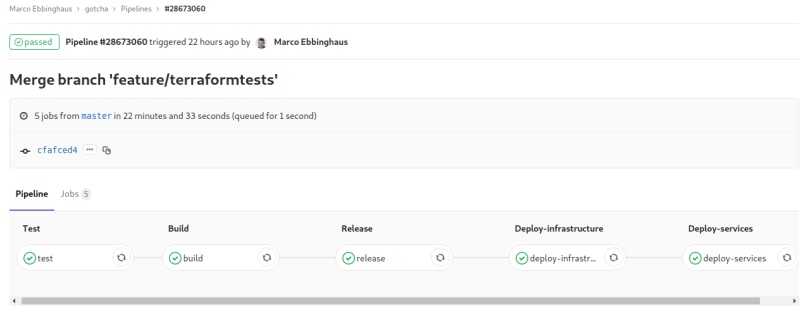
As you can see, it has 5 stages: test, build, release and deploy-infrustructure and deploy-services and they pretty much do, what their names tell:
The test-stage does a mvn clean test.
The build-stage does a mvn clean install and so generates the (spring boot) jar files which are in fact running in the docker containers containing the microservices.
The release-stage builds docker images (based on Dockerfiles) which contain and run the built jar files and pushes them to a SSL-secured docker registry which I installed on a hetzner cloud machine.
The deploy-infrastructure stage is where my server cluster for the docker swarm mode is created. This is done by creating 6 Droplets on DigitalOcean (the smallest ones for 5$ per month each). After creation some tools are installed on those machines (Docker, Docker Compose, GlusterFS Server/Client (for the volumes). When this stage is finished, I have a ready configured swarm mode cluster – but no services running on the swarm. This last step is done in the last stage.
Info on the cluster creation: The pipeline is (of course) idempotent. The server cluster during the deploy-infrastructure code is only created, if it is not already existent. To achieve this, I am using a „remote backend“ for terraform (in fact an aws S3 bucket). When terraform creates a server on e.g. DigitalOcean, a file called terraform.tfstate is created, which contains the information on which servers were created and what their state is. By using a backend for terraform, I tell terraform to save this file on a S3 bucket on aws. So the first time, the deploy-infrastructure stage is run, terraform will create the droplets and save their states in a file terraform.tfstate in the S3 bucket. Every continuing time the terraform stage is triggered, terraform will look into the file saved in the S3 bucket and will skip the creation as the file says, that they were already created.
The deploy-services stage is where my docker images are pulled from the external registry and deployed onto the (in the former stage) created droplets. For that to work, I am requesting the IP of one of the master (docker swarm) droplets via the DigitalOcean API and extracting the IP from the response, containing all created droplets. Then I am using ansible to execute the docker stack deploy command. This command pulls the needed docker images from the external registry and deploys containers on all worker nodes (as configured in the docker-compose.yml). A good thing about that command is, that it can also be used to deploy the services initially into the swarm, and also to update the services already running on the swarm. The docker-compose.yml looks like the following:
version: "3.6"
services:
index:
image: docker.gotcha-app.de/gotcha/index
deploy:
mode: global
ports:
- "8983:8983"
volumes:
- "index-volume:/opt/solr/server/solr/backup"
secrets:
- index-username
- index-password
crawler:
image: docker.gotcha-app.de/gotcha/crawler
deploy:
mode: replicated
replicas: 1
volumes:
- "crawler-volume:/root/nutch/volume"
secrets:
- index-username
- index-password
- crawler-api-username
- crawler-api-password
crawlergui:
image: docker.gotcha-app.de/gotcha/crawlergui
deploy:
mode: global
ports:
- "8082:8082"
secrets:
- crawler-api-username
- crawler-api-password
- crawler-gui-username
- crawler-gui-password
secrets:
index-username:
external: true
index-password:
external: true
crawler-api-username:
external: true
crawler-api-password:
external: true
crawler-gui-username:
external: true
crawler-gui-password:
external: true
volumes:
crawler-volume:
driver: local
driver_opts:
type: none
o: bind
device: /mnt/crawler-volume
index-volume:
driver: local
driver_opts:
type: none
o: bind
device: /mnt/index-volume
(If you are wondering where the secrets come from: They are creating inside the docker swarm on the deploy-infrastructure stage (during terraform apply) and are using the contents of environment variables which are created / maintained in gitlab. The volumes are also created during the terraform steps in the deploy-infrastructure stage.)
Summary
So what is happening after I push code changes:
The CI/CD-Pipeline of Gitlab starts and one stage is executed after another. If one stage fails, the pipeline fails in general and won’t continue. If everything works well: The jar files are created –>Docker-Images are pushed to my private docker registry –> the latest docker images are pulled from the registry and the running containers on my swarm cluster are updated one after another (or for the very first push: the cluster is created/intialized – which means: The Droplets are created on DigitalOcean and everything that is needed is installed/configured on those droplets (docker / docker compose / GlusterFS-Server/-Client / …) – all executed automatically by terraform. Then the pushed docker images are pulled and deployed automatically on the created/running cluster. The pipeline duration is about 20 minutes including the server cluster creation, and about 10 minutes if the server cluster is already running.
Right now it is already possible to access (for example) the crawler gui by calling <Public-IP-address-of-one-swarm-worker-droplet>:8082/crawlerui. The next steps will be adding a reverse proxy (probably traefik) which then redirects calls to the corresponding services and bind my domain with the swarm cluster nodes.
I like that tech stack a lot and I am looking forward to extend/improve the pipeline and the application. If you have suggestions / comments / questions feel free to leave them – I will appreciate it a lot!
Greetings!

[…] UPDATE: Ich habe meine Services inzwischen im Swarm Mode Cluster auf DigitalOcean ans laufen bekommen und habe auch die Volume-Problematik bereits gelöst. Allerdings bin ich nicht bei dem Docker-Volume-Plugin für DigitalOcean-Spaces geblieben (Problem war, dass ein Space jeweils nur einem einzigen Droplet zugeordnet werden konnte..ich hatte es mir eher so vorgestellt, dass wenn ich 3 Swarm Mode Nodes habe, dann allen dreien den selben Space zur Verfügung stellen kann). Stattdessen installiere ich nun auf allen Master-Nodes einen GlusterFS-Server-Verbund mit zwei Volumes (crawler und index) und auf allen Worker-Nodes installiere ich den GlusterFS-Client und mounte dort jeweils die GlusterFS-Volumes, sodass im Endeffekt auf jedem Worker beide Volumes zu jeder Zeit im selben Zustand vorhanden sind. Mehr dazu findet ihr in folgendem Blog-Post: CI/CD-Pipeline for a java microservice application running on Docker Swarm mode cluster on DigitalOc… […]
LikeLike